NILFS2 en Linux
Éste artículo explicará la presentación impartida en COSIT 2012 nombrada Diseño e Implementación del Sistema de Archivos NILFS2 en Linux; de manera más informativa, para las personas que no la hayan presenciado y también para quienes gusten de tenerla al alcance.
¿Qué hace un Sistema de Archivos?#
Lo primero, necesitamos saber, ¿qué hace un sistema de archivos? ¿Por qué es tan importante?
El Sistema de Archivos es uno de los componentes de un Sistema Operativo que se encarga de salvaguardar los datos e información, organizarla y estructurarla de tal manera que las aplicaciones que usamos, como usuarios; podamos acceder a ésta y no perderla. Entonces, debe de cumplir las siguientes características1:
Almacenamiento persistente de datos
Debemos de poder recuperar la información después de prendidos y apagados del sistema; almacenándose en algún medio persistente, como un disco duro.
Darle un significado
Para organizar nuestra información, debe de almacenarse de forma que los usuarios sepan de qué es, colocándola en un archivo y darle un nombre.
Organizado de datos
Mientras se va guardando más información, se deben de agrupar archivos similares dentro de carpetas y sub-carpetas.
Reconocimiento de Tipos de Archivos
Para que las Aplicaciones puedan reconocer qué archivos pueden abrirse o que el usuario sepa qué aplicación usar; se pueden usar cabeceras en los archivos que describen qué tipo de archivo es, o usar extensiones en los nombres.
Acceso a los Archivos
Los programas deben de poder acceder a los archivos, sin importar el medio donde se encuentren, y poder acceder a datos de éstos de manera aleatoria.
Atributos en los Archivos
Se definen los privilegios y protección de los archivos y directorios, ya sea contraseñas, creador, dueño, oculto, de sistema, etcétera.
Operaciones en Archivos y Directorios
Las operaciones son crear, borrar, abrir, cerrar, leer, escribir, adjuntar, buscar, conseguir atributos, definir atributos, renombrar y bloquear.
Sistemas de Archivos Tradicionales#
Los Sistemas de Archivos existen como tal desde hace ya varias décadas; y no han cambiado mucho desde entonces, ya que su función se cumple sin muchos problemas. Los Sistemas de Archivos tradicionales actualizan y modifican los datos, accediendo al disco de manera aleatoria. Por ejemplo, supongamos que a un archivo acabamos de adjuntarle nueva información.

El Sistema Operativo, tiene que hacer las siguientes operaciones:
- Se actualiza el nodo índice del directorio, indicando si los bloques del directorio y sus archivos han sido modificados.
- Los meta-datos del directorio que contiene el archivo se modifican, donde indica que su fecha de acceso ha sido modificada.
- Se actualiza la lista de archivos que contiene el directorio, indicando que un archivo fue modificado.
- Se actualizan los meta-datos y nodo índice del archivo que modificamos, indicando que la fecha de acceso, la fecha de modificación y su tamaño han sido modificados.
- Los nuevos datos tienen que ser escritos en los bloques libres, a veces en ubicaciones no contiguas al resto de los datos originales.
Ahora bien, a nivel hardware, y que los discos duros cuentan con Cache, el orden puede variar, pero de manera lógica así se sigue; y vemos que se hicieron 5 o más escrituras en el disco, de manera aleatoria.
Un Sistema de Archivos tradicional, visto como funciona, cuenta con las siguientes características:
Sistema usado por mucho tiempo
Útil para almacenamiento en un medio simple
Pueden perderse datos en caso de apagado incorrecto
Si hay una falla eléctrica el disco duro probablemente no pudo completar todas las operaciones programadas, perdiendo datos.
Mucho tiempo de recuperación de caída
Se necesitan recorrer todos los datos dentro del sistema de archivos, detectando operaciones incompletas, borrando datos huérfanos.
Aumenta tiempo de búsqueda
Los bloques de nodos índice y meta-datos muchas veces no cambian de lugar, si hay muchas modificaciones concurrentes, el tiempo de búsqueda de los bloques que tienen que modificarse tienden a distanciarse y el disco tarda más tiempo en ubicarlos.
Aumenta fragmentación
Los datos dejan de estar en bloques contiguos.
Sistemas de Archivos con Bitácora#
Al conocer a los Sistemas de Archivos Tradicionales, y con la importancia de salvaguardar la información en los discos; se debió de crear una manera de mantener la información modificándose al momento de una caída.
Aparecieron entonces los Sistemas de Archivos con Bitácoras (Journaling File Systems) con los siguientes principios:
Escrituras secuenciales rápidas, escrituras aleatorias lentas
Los datos deben de ubicarse en bloques contiguos lo mejor posible, para disminuir los tiempos de búsqueda.
Operaciones de Meta-datos requieren de múltiples escrituras a diferentes datos
Los meta-datos tienen bloques especiales, y se deben de escribir antes de los bloques de datos, para mantener la integridad de la información.
Mejorar consistencia de datos
Los datos deben de mantenerse consistentes después de una falla.
El primer Sistema de archivos de éste tipo fue JFS, diseñado por IBM en 1990.
Las operaciones en los datos primero se escriben a una bitácora, la cual puede ser un disco separado o una sección reservada del mismo disco de información, y después los datos se ordenan en su lugar, de manera contigua.
Los JFS operan a grandes rasgos, de la siguiente manera:
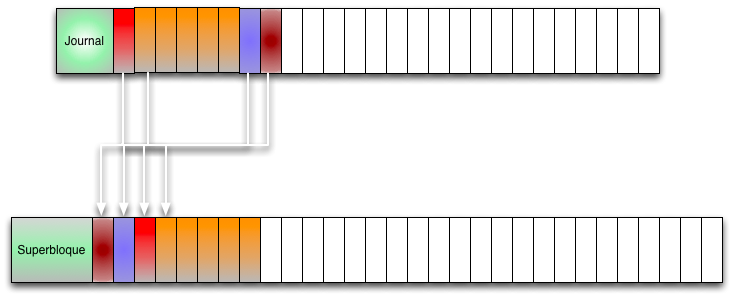
Se tiene la bitácora y la información que alberga el sistema de archivos. En la bitácora se anotan las operaciones que tienen que llevarse a cabo, en estricto orden, una vez que se estimaron las operaciones que tienen que hacerse, se empiezan a hacer dentro del sistema de archivos.
Los JFS tienen como ventajas:
Escribe registros secuenciales para demorar escrituras aleatorias
Facilita la recuperación rápida
Leyendo las operaciones pendientes en la bitácora y escribiéndolas en el volumen.
Claro está, el JFS puede tener éstos obstáculos:
- Si no se escribe en bitácora, se queda el volumen intacto, perdiendo los datos
- Si se escribe en bitácora, y el volumen tuvo operaciones pendientes, puede reescribir datos
Los JFS pueden trabajar en 3 modos2:
Writeback
Solo los meta-datos se escriben en la bitácora, mientras que la información se reescribe en el volumen.
Ordered
Los meta-datos se escriben en la bitácora, y se garantiza que la información se escriba en el disco antes de indicar en la bitácora que la información está consistente.
Data
Los meta-datos e información se escriben en la bitácora antes de escribir en el volumen.
Los JFS son funcionales en la gran mayoría de los casos donde es importante mantener la integridad de la información después de una caída.
Sistemas de Archivos con Bitácora Estructurada#
Éstos Sistemas de Archivos aparecieron en 1988, por el trabajo de Ousterhout, Douglis y Rosenblum1 3 4, con la característica que los datos que se actualizan, sean nodos índice, meta-datos o información, simplemente se escriben en el siguiente bloque disponible.
Los LFS ordenan sus datos diferente a los JFS

El disco es la misma bitácora, teniendo las siguientes ventajas:
- Escritura secuencial
- Reducción de tiempo de búsqueda
- Control y manejo de estado (versiones) de datos
- Recuperación de operaciones del Sistema de Archivos inmediata
Pero… Hay desventajas:
Aumenta su espacio en disco
El disco se puede quedar sin bloques disponibles ya que siempre está escribiendo secuencialmente.
Aumenta fragmentación en ciertas condiciones
Si hay una herramienta que recorre el disco liberando bloques que ya no contengan información útil, quedan repartidos de manera aleatoria en todo el disco.
NILFS2#
NILFS2 significa New Implementation of a Log-Structured File System version 2, y fue desarrollado por Nippon Telegraph and Telephone Corporation; de licencia GPL; que forma parte del núcleo de Linux a partir de su versión 2.6.30. Antes de éste, no se habían incorporado otros LFS similares a Linux; pero la forma de operar los LFS, son muy útiles para Discos Duros de Estado Sólido (SSD).
Vamos a ver con más detalle, el proceso de escritura.
Tenemos 2 archivos, en el archivo A se hará la operación de búsqueda y escritura, mientras en el archivo B se adjuntarán datos.
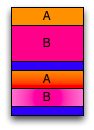
Se tienen los archivos A y B originales con el Bloque Super Root (SRB) indicando su estado.
Luego tenemos las operaciones seek() y write() sobre archivo A,
secuencialmente, la operación append() sobre archivo B y después, el
SRB actualizado en un nuevo bloque.
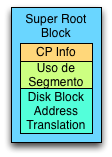
El Bloque Súper Root (Super Root Block) contiene información de la estructura del sistema de archivos, como lo que es información del último Checkpoint, información del segmento de datos que alberga, y la tabla de traducción de direcciones de bloques de disco (Disk Block Address Translation).
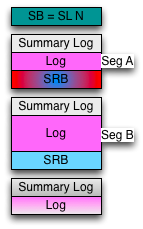
A todo esto, ¿cómo se recupera NILFS2 después de una caída? Muy simple:
- Lee el último estado de la bitácora contenido en el Súper Bloque.
- Busca si en el estado de la bitácora se tiene un SRB y un Checksum válido.
- Si no es válido, recorre el disco buscando el SRB anterior.
- Empieza a trabajar a partir de ese segmento.
- Si hubo datos después, serán marcados como libres y serán re-escritos.
¿Qué pasa si se tienen bloques con datos de archivos que están marcados como borrados después de un tiempo y el nivel de bloques disponibles es bajo?
NILFS2 tiene un recolector de basura (Garbage Collector) cuya tarea es liberar y optimizar segmentos eliminando Checkpoints viejos, pero sin tocar los Snapshots.

El Garbage Collector recorre los segmentos, al encontrar bloques con información que ha sido modificada subsecuentemente en otros segmentos, crea un nuevo segmento y coloca toda la información relacionada de manera contigua, marcando los bloques libres que fueron usados anteriormente.
Características#
NILFS2 tiene las siguientes características:
- Control de Versiones
- Restauración de datos modificados o borrados: De segundos antes.
- Checkpoints automáticos
- Snapshots: Checkpoints marcados.
- Los Snapshots son de sólo lectura
- Recolección de Basura en línea
- Manejo de datos en Árboles Binarios
- Estructuras de datos en 64 bits: Puede albergar archivos y manejar volúmenes de hasta 8 Exabytes (8,388,608 Terabytes) de tamaño. El tamaño del volumen debe de ser al menos 128MB.
- Control de fechas en 64 bits
- Módulo de núcleo más herramientas de administración
Carencias#
En NILFS2 aún hay desarrollo pendiente, como:
- Atributos extendidos
- Listas de control de acceso
- Quotas
- File System Check
- De-fragmentador en línea
Utilidades#
mkfs.nilfs2
Crea el sistema de archivos.
mount.nilfs2
Monta el sistema de archivos.
nilfs-clean
Administrador del Recolector de Basura.
nilfs-resize
Ajustador del tamaño en línea.
nilfs-tune
Ajuste de parámetros del sistema de archivos.
nilfs_cleanerd
Servicio de Recolección de Basura.
umount.nilfs2
Desmonta el sistema de archivos.
chcp
Marca o demarca Snapshots desde algún Checkpoint.
dumpseg
Imprime información de algún segmento.
lscp
Lista los Checkpoints del sistema de archivos.
lssu
Lista el estado de uso de los segmentos.
mkcp
Crea un Checkpoint o Snapshot.
rmcp
Elimina un Checkpoint existente.
-
Tanenbaum, Andrew S; Woodhull, Albert S, Operating Systems: Design and Implementation, 3rd ed. (Pearson / Prentice Hall, 2006) ↩︎ ↩︎
-
Prabhakaran, Vijayan; Arpaci-Dusseau, Andrea C; Arpaci-Dusseau, Remzi H, Analysis and Evolution of Journaling File Systems, 2005 USENIX Annual Technical Conference. ↩︎
-
McKusick, Marshall K; Bostic, Keith; Karels, Michael J; Quaterman, John S, The Design & Implementation of the 4.4BSD Operating System (Addison-Weasley Longman, 1996) ↩︎
-
Rosenblum, Mendel, Ousterhout, John K, The Design and Implementation of a Log-Structured File System, ACM Transactions on Computer Systems, Vol. 10 Issue 1. 1992 ↩︎